Google Gemma 4 12B开源:120亿参数16GB内存即可跑,首款原生音频中型模型
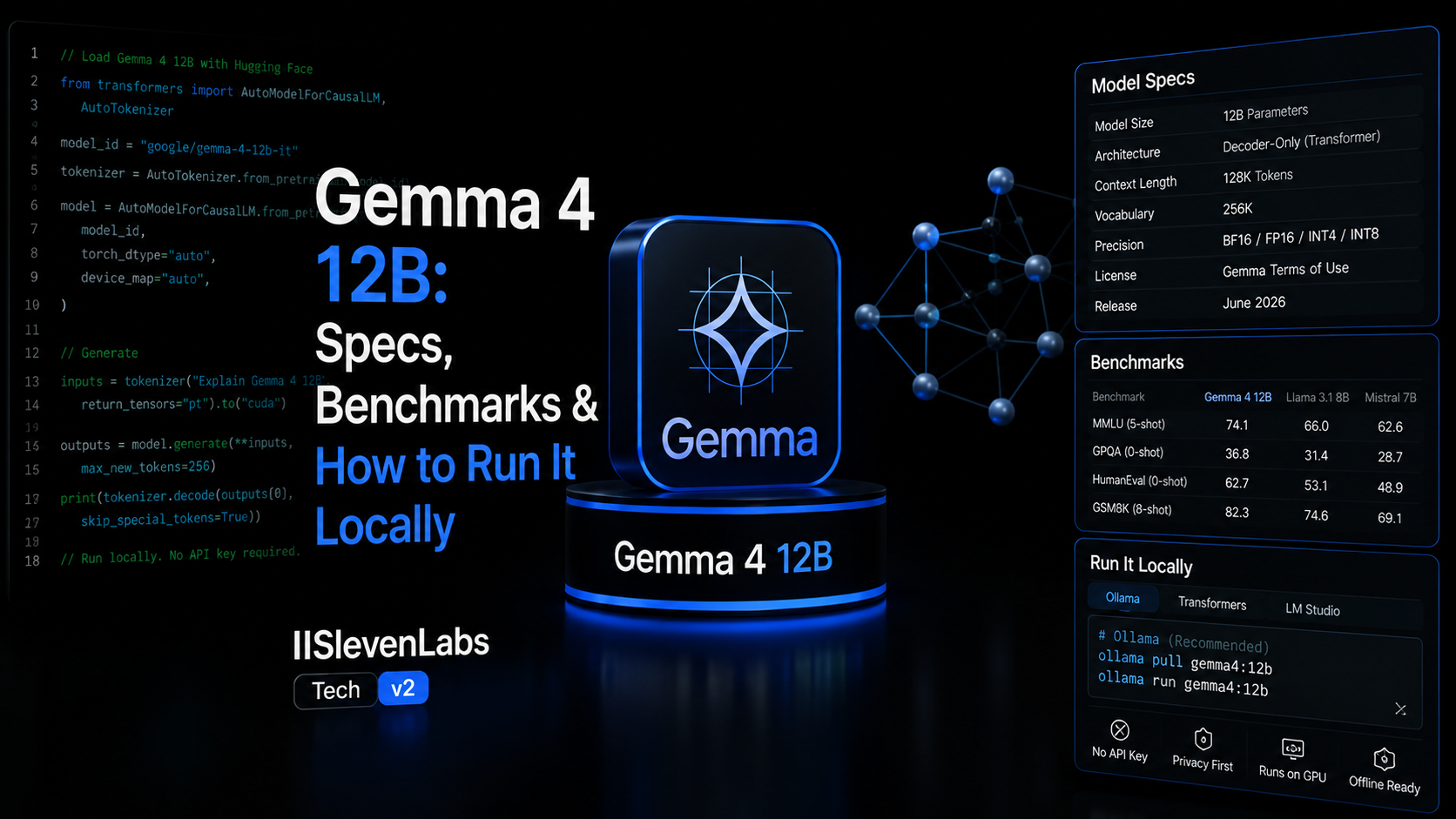
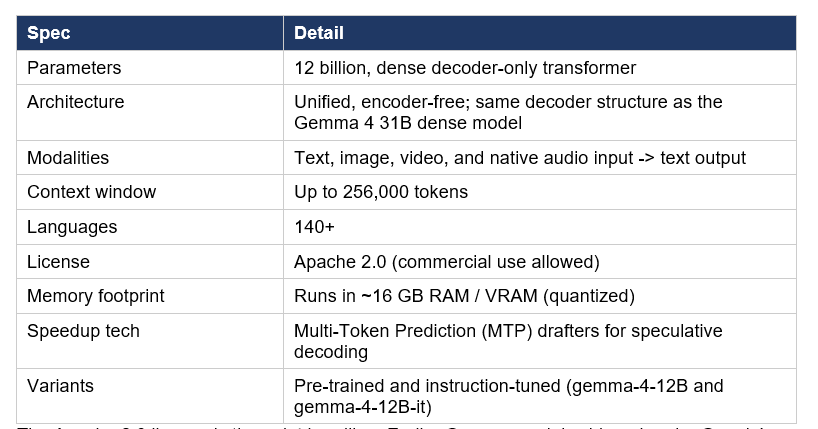
Google DeepMind 于 6 月 3 日正式发布 Gemma 4 12B,这是 Gemma 家族首款原生支持音频输入的中型多模态模型。核心卖点:120 亿参数,16GB 内存即可本地运行,性能接近自家的 26B MoE 大模型,但内存占用不到一半。
架构创新
Gemma 4 12B 采用统一编码器自由架构(Encoder-Free)——去掉了传统多模态模型中的视觉和音频编码器,让 LLM 主干网络直接处理图像和音频信号。这意味着更低的延迟、更少的内存开销,以及更简洁的推理管线。
模型内置 Multi-Token Prediction(MTP)推测解码器,一次可预测多个后续 token,加速推理过程,且无需重新训练即可获得提速效果。
多模态能力
Gemma 4 12B 原生支持四种模态输入:文本、图像、音频和视频。上下文窗口高达 256K tokens,覆盖 140+ 种语言。实际测试中可处理如"5 分钟视频(313 帧)+ 同步音频"的联合输入场景。
在基准测试方面,社区报告显示 GPQA Diamond 达到 78.8%,DocVQA 达到 94.9%——对于 12B 级别的模型来说表现相当突出。官方确认其在标准基准上已接近 26B MoE 的水平,同时显著超越上一代 Gemma 3 27B。
模型对比
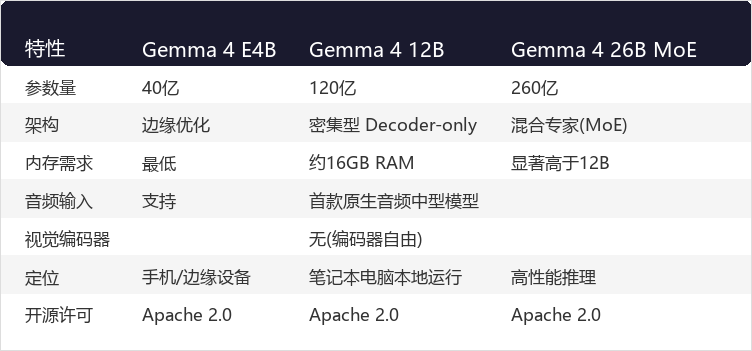
开发者生态
Google 为 12B 提供了完整的工具链支持:Ollama 一行命令拉取即跑、LM Studio 图形化界面体验、llama.cpp 精细控制量化参数、MLX 在 Apple Silicon 上利用统一内存加速。微调方面,Unsloth AI 已发布优化版本,单张消费级 GPU 即可完成高效微调。
截至目前,Gemma 4 全系列累计下载量已突破 1.5 亿次。对于想要在笔记本上跑多模态 AI 的开发者来说,12B 是目前性价比最优的选择之一。
来源:
- Google Blog / Google Developers Blog / BuildFastWithAI(英文源)

当前文章标题:Google Gemma 4 12B开源:120亿参数16GB内存即可跑,首款原生音频中型模型
当前文章地址:https://www.2109.top/3971/
来源:2109博客 地址:https://2109.top 文章版权归作者所有,未经允许请勿转载。
转载及其他合作需求请微信联系博主