MiniMax预告旗舰模型M3:稀疏注意力架构,百万Token解码提速15.6倍
2T超大容量网盘!点击领取 >> 原画质高清备份,上传下载不限速
上海AI实验室MiniMax预告了其下一代旗舰模型M3,采用突破性的稀疏注意力架构,有望重塑超长上下文AI的经济模型。核心创新是一种自定义稀疏注意力机制,在百万Token解码场景下可实现最高15.6倍的提速,且无需压缩键值状态。

M3核心技术规格:
| 特性 | 详情 |
|---|---|
| 架构 | MiniMax稀疏注意力(MSA) |
| 上下文窗口 | 最高100万Token |
| 解码提速 | 最高15.6倍(@1M tokens) |
| KV缓存 | 无压缩,保留完整精度 |
| 推理成本 | 预计降低90%+ |
| 预训练数据 | 超10万亿Token |
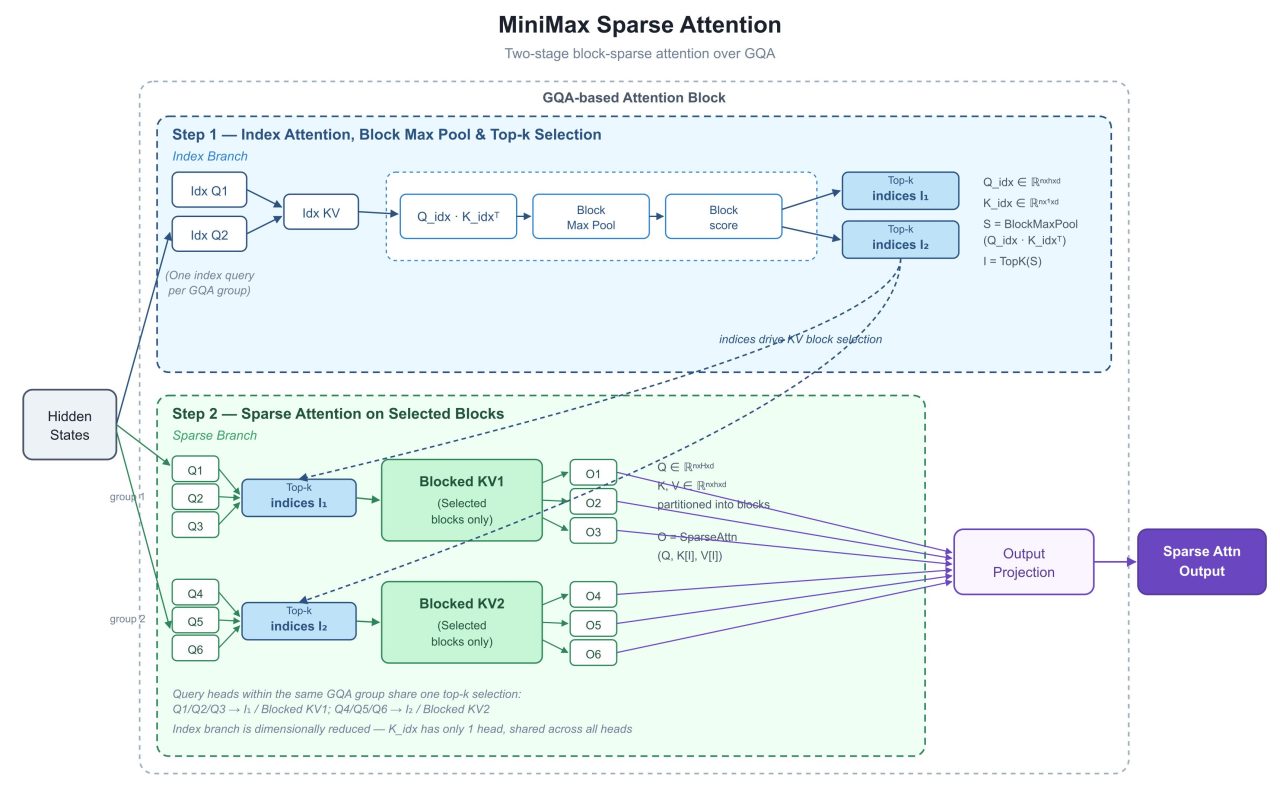
MSA(MiniMax Sparse Attention)的工作原理分为两个阶段:首先由轻量级索引分支扫描输入Token并筛选相关历史Token块,然后仅对这些选中的块执行注意力计算——使用真实、未压缩的KV状态。这种方法不同于当前主流的KV缓存量化或滑动窗口方案,没有召回率损失。
外部开发者预览显示,M3在编程、长文档理解和多轮对话任务中表现显著优于前代M2.5。在百万Token级别的"大海捞针"测试中,M3保持了近乎完美的召回率,而大多数竞品在此长度下已显著退化。
MiniMax尚未公布M3的具体发布日期和定价,但表示将通过API和开源两种方式提供。
来源:VentureBeat, FelloAI, TheAICronicle
2T超大容量网盘!点击领取 >> 原画质高清备份,上传下载不限速

如果真的对你有用的话,感谢支持服务器及作者运营
当前文章作者名:Ai
当前文章标题:MiniMax预告旗舰模型M3:稀疏注意力架构,百万Token解码提速15.6倍
当前文章地址:https://www.2109.top/3809/
来源:2109博客 地址:https://2109.top 文章版权归作者所有,未经允许请勿转载。
转载及其他合作需求请微信联系博主
当前文章标题:MiniMax预告旗舰模型M3:稀疏注意力架构,百万Token解码提速15.6倍
当前文章地址:https://www.2109.top/3809/
来源:2109博客 地址:https://2109.top 文章版权归作者所有,未经允许请勿转载。
转载及其他合作需求请微信联系博主
THE END